Les routines de Lodex sont des scripts, fournis par Lodex ou stockables n’importe où sur le web, qui peuvent effectuer des agrégations, des calculs, des reformatages et renvoyer des données sous une forme utilisable (souvent un format de type graphique).
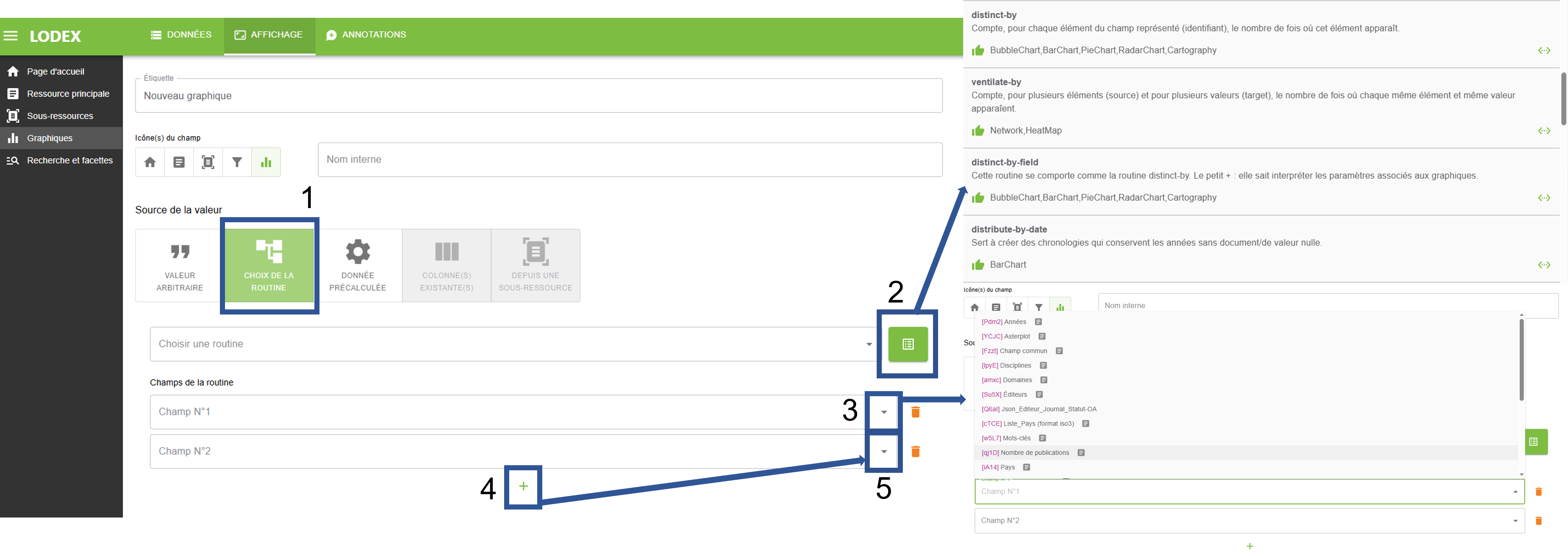
Les routines sont appelées via l’API web de Lodex, et s’appliquent à un champ (ou plusieurs) dans le but de créer un flux JSON principalement utilisable dans le cadre de la création de graphiques et parfois pour certains champs créés dans la partie « Ressource principale » (c’est notamment le cas du graphique « Asterplot » qui permet de naviguer de ressource en ressource en fonction des similarités des champs appliqués à la routine pour générer ce type de graphique). Depuis la version 14 de LODEX, les routines disponibles sont sélectionnables si l’icône « CHOIX DE LA ROUTINE » est sélectionné (1) en tant que source de la valeur du champ à créer. Ceci s’effectue via une liste déroulante en cliquant sur l’icône vert (2) dans l’onglet « GÉNÉRAL » lors de la création d’un champ que ce soit dans la partie « Graphiques » ou « Ressource principale » (voir la partie Création ou modification d’un modèle). Une deuxième liste déroulante (3) permet de sélectionner le champ sur lequel la routine va s’appliquer et il est aussi possible d’ajouter d’autres champs en cliquant sur le symbole « + » (4) pour générer une ou plusieurs autres listes déroulantes (5) afin de sélectionner des champs supplémentaires.
Déclaration des routines dans le fichier de configuration
Pour qu’une routine soit utilisable dans LODEX via son API, il faut qu’elle soit déclarée dans le champ routine du fichier de configuration.
Le nom de la routine doit être exactement le même que celui du fichier en ligne (avec l’extension .ini) : voir la partie « Les paramètres d’une instance« .
Sélection d’une routine et application à un ou plusieurs champs
Lors de la création et du paramétrage du champ d’un modèle d’une instance Lodex, la routine et les champs sur laquelle elle s’applique doivent être déclarés: lorsque « CHOIX DE LA ROUTINE » est sélectionné comme source de la valeur du champ. Ci-dessous, un exemple d’utilisation de la routine « distinct-by » appliquée à un champ nommés « Années » permettant ainsi l’accès à la production d’un diagramme à barres (par exemple en fonction du format choisi ensuite) présentant le nombre de documents publiés par année.
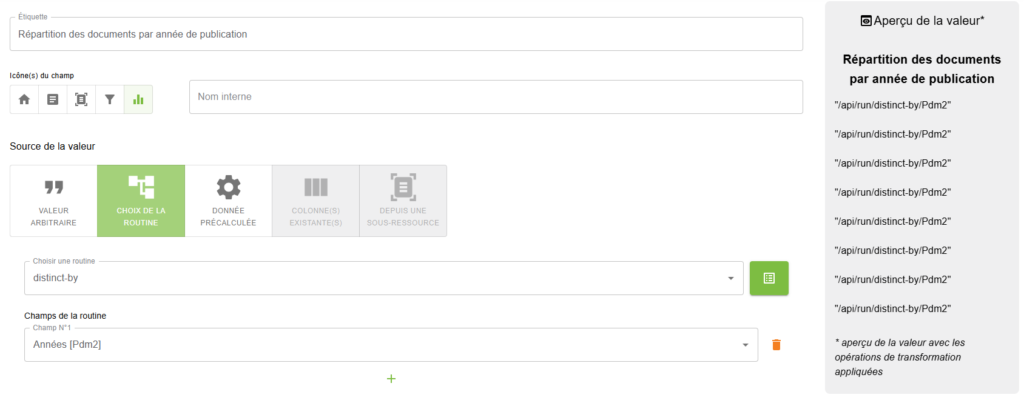
L’aperçu de la valeur montre quelle routine est utilisée et sur quel(s) champ(s) elle s’applique via le code à 4 caractères attribué par LODEX à ce(s) dernier(s). Le résultat d’une routine peut être visualisé en formatant le champ avec le format « Autre – Format Json et Débogage » :
Le choix de la routine se fait en fonction du format d’affichage souhaité (type de graphique par exemple). Dans certains cas, il est possible de pouvoir utiliser plusieurs routines pour un même format.
La description des routines et des graphiques déclinée dans les parties suivantes a pour but de préciser la ou les routines utilisables pour afficher le type de graphique souhaité par exemple, ou d’autres formats.
Routines disponibles dans Lodex (de la routine aux graphes)
all-documents
Donne, pour tout le corpus, tous les champs de tous les documents en JSON avec les champs _id, publicationDate, uri, et total (cf. « labeled-resources » qui renvoie le même résultat sans ces champs supplémentaires).
Cette routine est particulièrement utile pour le format « Graphique – Syntaxe Vega-Lite ».
Comme elle retourne tous les champs, aucun champ n’est fourni en paramètre.
Attention: ce sont les identifiants des champs qui sont fournis, pas leurs libellés.
Remarque : L’utilisation de cette routine n’est pas recommandée lors de travaux sur des « datasets » massifs, car cela équivaut à exporter l’ensemble de la base de données dans la mémoire du navigateur ce qui peut provoquer de gros ralentissements en fonction de la mémoire vive disponible, de la taille du corpus et du nombre de champs.
classif-by
Elle est destinée à un type de graphique permettant de visualiser les évolutions diachroniques du poids de thématiques contenues dans les documents d’un corpus.
Cette routine est destinée à être utilisée avec le format graphique : « Graphique de flux ».
close-by
Cette routine est utilisée pour créer le graphique « Aster Plot ».
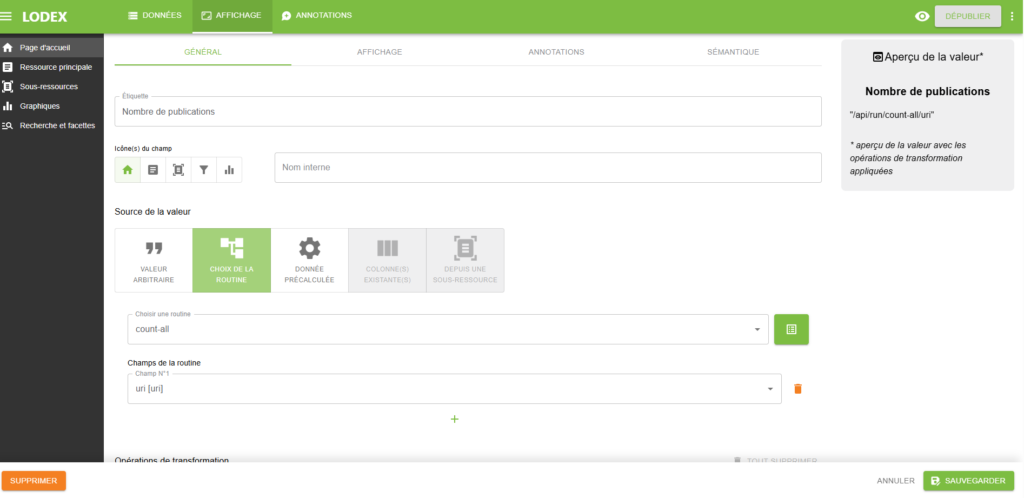
count-all
Cette routine compte le nombre de documents du corpus. Ce calcul est dynamique, le nombre de documents se met à jour automatiquement si on ajoute un ou plusieurs fichiers supplémentaires au corpus
Elle peut être utilisée, par exemple, avec le format Texte – Chiffre en gras pour afficher le nombre de documents sur la page d’accueil de l’instance.
Elle doit alors être déclarée dans « Comment la valeur est créée » selon : /api/run/count-all/
Exemple d’utilisation de cette routine en page d’accueil (ex: on peut compter les « uris » dont on sait qu’ils sont uniques) :

count-by-fields
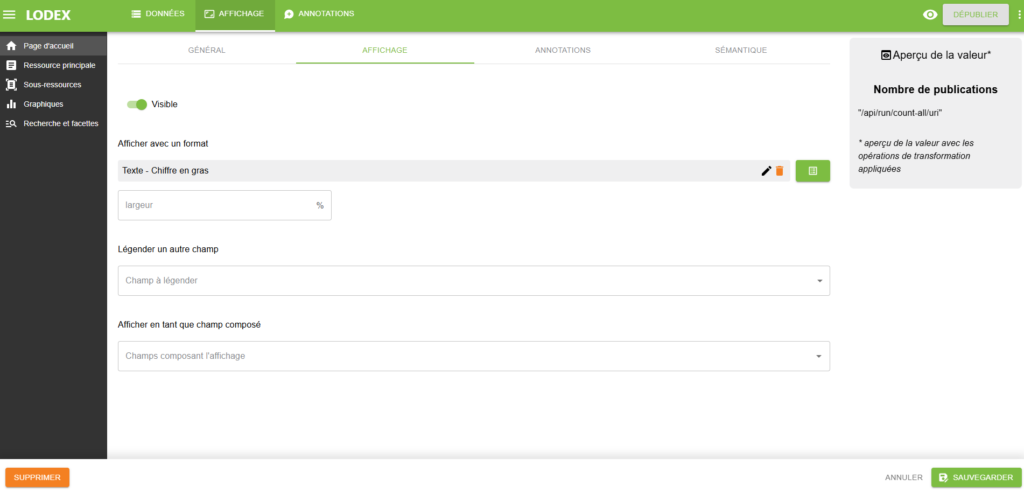
Cette routine compte le nombre de documents du corpus pour chacun des champs déclarés dans le modèle et renvoie les résultats selon le format JSON format suivant où l’identifiant « _id » de chaque champ correspond au code à 4 chiffres attribué à chaque champ par Lodex lors de leur création.
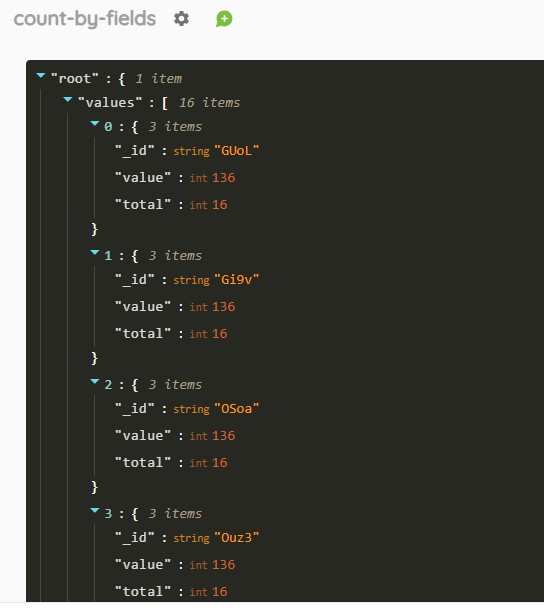
cross-by
Croise les éléments pour un champ ou plusieurs champs et compte le nombre d’occurrences de chaque croisement.
Crée les paires (source et cible) entre les éléments de 2 champs (champs identiques ou différents) déclarés selon :
- /api/run/cross-by/identifiant1/identifiant1/
- /api/run/cross-by/identifiant1/identifiant2/
et compte, pour chaque paire, le nombre de co-occurrences.
Cette routine se comporte comme la routine pairing-with , le petit +: elle sait interpréter les paramètres associés aux graphiques:
- Nombre max de champs
- Valeur maximum à afficher
- Valeur minimum à afficher
- Trier par valeur/label
Elle peut, en particulier, être utilisée avec les formats Réseau et Carte de chaleur.
Attention : dans le cas où cette routine s’applique à un seul champ (/api/run/cross-by/identifiant1/identifiant1/), elle conserve les auto-paires (source et cible identiques). Cela peut être intéressant avec le format Carte de chaleur pour visualiser la diagonale, mais peut être gênant avec d’autres formats.
Le format JSON renvoyé est sous la forme {« source », « target », « weight ») :
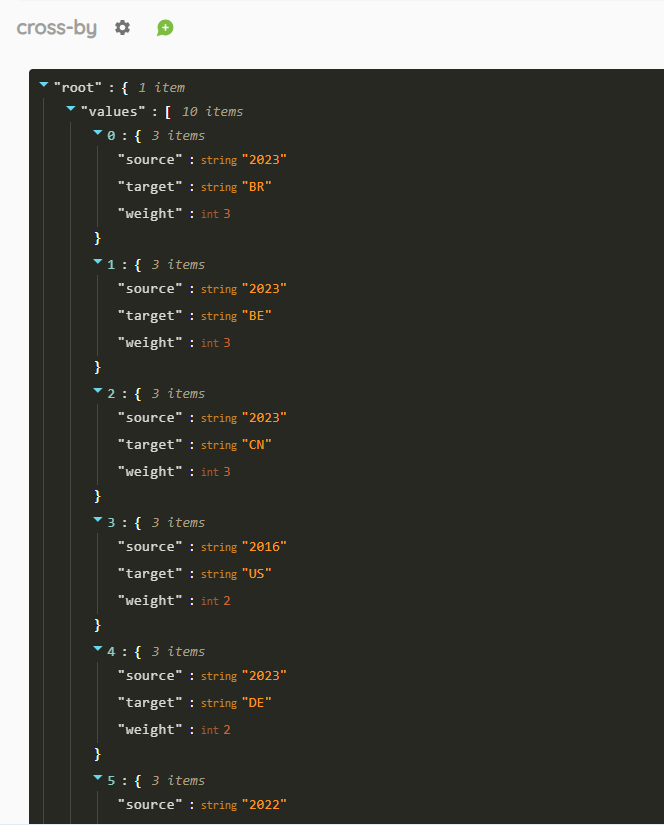
decompose-by
Croise les éléments pour un champ ou plusieurs champs et compte le nombre d’occurrences de chaque croisement.
Crée les paires (source et cible) entre les valeurs de 1 champ ou plusieurs champs (champs identiques ou différents) selon :
/api/run/decompose-by/identifiant1/
/api/run/decompose-by/identifiant1/identifiant2/
et compte, pour chaque paire, le nombre de co-occurrences.
Cette routine se comporte comme la routine graph-by, le petit +: elle sait interpréter les paramètres associés aux graphiques :
- Nombre max de champs
- Valeur maximum à afficher
- Valeur minimum à afficher
- Trier par valeur/label
Elle peut, en particulier, être utilisée avec les formats Réseau et Carte de chaleur.
Attention : dans le cas où cette routine s’applique à plusieurs champs (/api/run/decompose-by/identifiant1/identifiant2/), elle crée les paires identifiant1/identifiant2 mais aussi identifiant1/identifiant1 et identifiant2/identifiant2, ce qui peut ne pas être adapté pour un réseau.
À la manière de « cross-by », le format JSON renvoyé est sous la forme {« source », « target », « weight »).
distinct-ISO3166-1-alpha2-from
Fournit le nombre de fois où un pays apparaît selon son :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Elle est, en particulier, utilisée avec le format Cartographie pour représenter les pays d’un corpus sur une carte du monde.
Attention : avant d’utiliser cette routine, il peut être utile de vérifier que les formes d’écriture des pays verbalisés du corpus correspondent bien aux formes d’écriture des pays dans la table de correspondance.
distinct-ISO3166-1-alpha3-from
Transforme les valeurs verbalisées du champ pays en leurs codes ISO 3 et compte le nombre de fois où ce pays apparaît (code ISO 3), selon son :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Elle est, en particulier, utilisée avec le format Cartographie pour représenter les pays du corpus sur une carte du monde.
Attention : avant d’utiliser cette routine, il peut être utile de vérifier que les formes d’écriture des pays verbalisés du corpus correspondent bien aux formes d’écriture des pays dans la table de correspondance.
distinct-alpha-2-alpha3-from
Transforme les codes ISO 2 du champ pays en leurs codes ISO 3 et compte le nombre de fois où ce pays apparaît (identifiant), selon son :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Elle est, en particulier, utilisée avec le format Cartographie pour représenter les pays du corpus sur une carte du monde.
Attention : avant d’utiliser cette routine, il peut être utile de vérifier que les codes ISO 2 des pays du corpus correspondent bien aux codes ISO 2 dans la table de correspondance (faire une lien vers une table des correspondances des codes ISO 2 et ISO 3)
distinct-alpha-3-alpha2-from
Transforme les codes ISO 3 des pays du champ représenté en leurs codes ISO 2 et compte le nombre de fois où ce pays (identifiant) apparaît selon son :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Elle est, en particulier, utilisée avec le format Cartographie pour représenter les pays d’un corpus sur une carte du monde.
Attention : avant d’utiliser cette routine, il peut être utile de vérifier que les codes ISO 3 des pays du corpus correspondent bien aux codes ISO 3 dans la table de correspondance.
distinct-alpha-3-ISO3166-1-from
Transforme les codes ISO 3 des pays du chams représenté en leurs intitulés verbalisés (Anglais ou Français) et compte le nombre de fois où ces pays apparaissent selon leur :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Elle est, en particulier, utilisée avec le format Cartographie pour représenter les pays d’un corpus sur une carte du monde.
Attention : avant d’utiliser cette routine, il peut être utile de vérifier que les verbalisations des pays du corpus correspondent bien aux codes ISO 3 dans la table de correspondance.
distinct-alpha-3-ISO639-from
Transforme les codes ISO 3 des langues du champ représenté en leurs intitulés verbalisés.
distance-with
Cette routine accepte des arguments (champs) multiples dans le but de comparer 2 ressources sur la base des contenus des champs sur lesquels elle s’applique. Le flux JSON renvoyé est illustré ci-dessous et se présente sous la forme {« source », « target », « weight », « target_title », « target_summary »}. La valeur de la clé « weight » correspond au % de similarité entre la ressource consultée (« source ») et une autre du corpus « target ». Ce pourcentage est calculé en faisant la moyenne des « sous-clés » « weights » correspondant aux % de similitude entre chaque champ indiqués comme arguments de la routine. Dans cet exemple , il s’agit d’un corpus de 63 documents (donc 62 résultats ») et les champs comparés sont à titre indicatif le domaine, la discipline, le sous-champ disciplinaire et la thématique de chacune de ces publications).
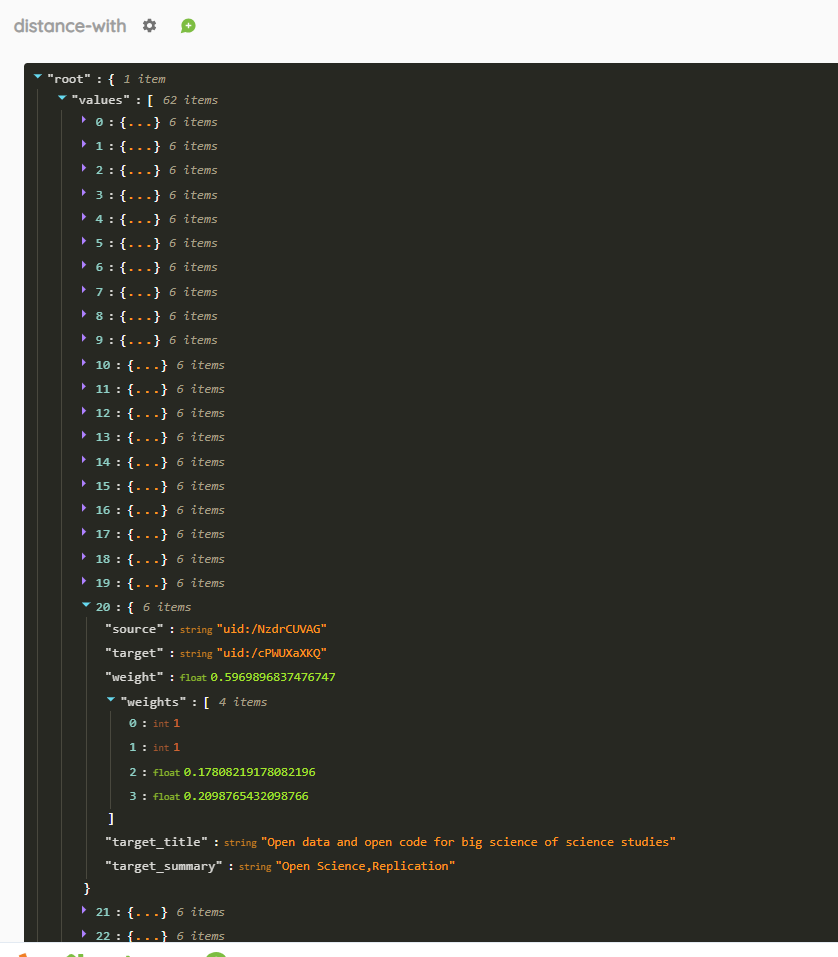
À utiliser avec le format graphique « Coordonnées parallèles ».
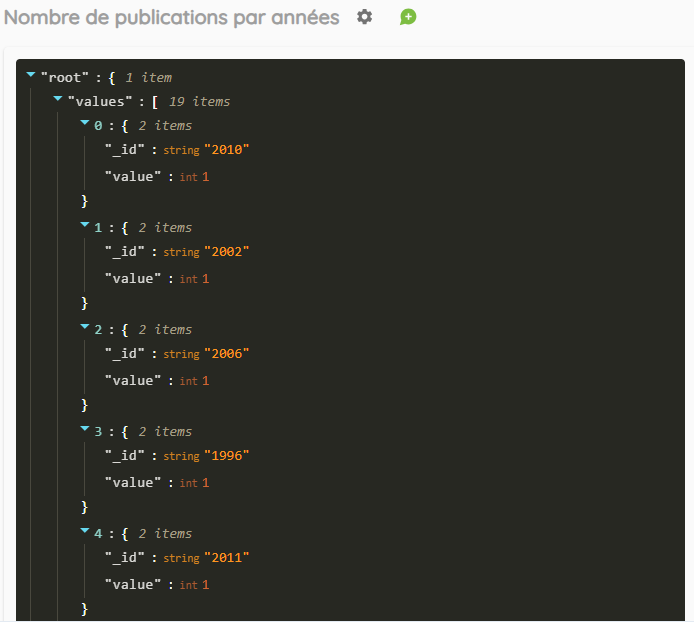
distinct-by
Compte, pour chaque élément du champ représenté (identifiant), le nombre de fois où cet élément apparaît selon son :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Cette routine se comporte comme la routine distinct-by-field. Contrairement à celle-ci, elle n’interprète pas les paramètres associés aux graphiques.
Cette routine peut être utilisée avec les formats graphiques :
- Graphe à bulles
- Diagramme en barres
- Diagramme circulaire
- Diagramme Radar
- Cartographie (si code ISO 3 ou code ISO 2 des pays)
Le flux JSON renvoyé se présente selon la structure {« _id », « value »}. Voici ci-dessous un exemple le résultat JSON obtenu pour l’application de cette routine à un champ « Année de publication »
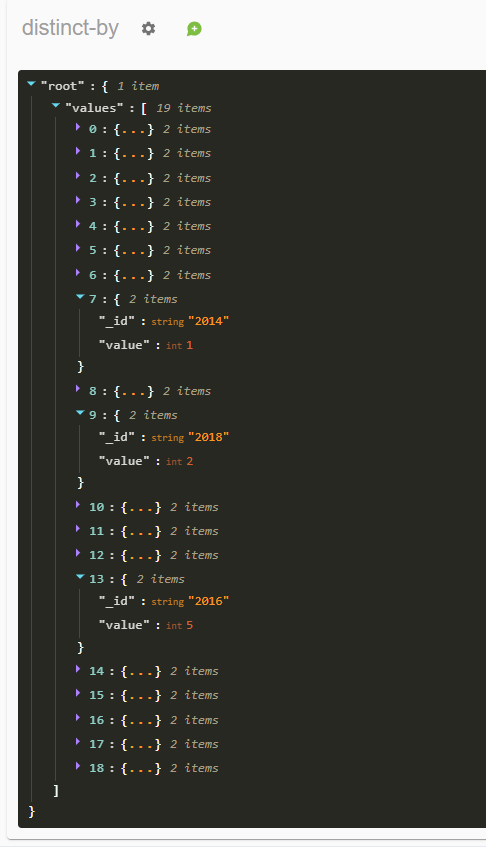
distinct-by-field
Compte, pour chaque élément du champ représenté (identifiant), le nombre de fois où cet élément apparaît selon son :
- nombre d’occurrences si le champ n’est pas dédoublonné
- nombre de documents si le champ est dédoublonné
Cette routine se comporte comme la routine distinct-by, le petit +: elle sait interpréter les paramètres associés aux graphiques :
- Nombre max de champs
- Valeur maximum à afficher
- Valeur minimum à afficher
- Trier par valeur/label
Cette routine peut être utilisée avec les formats graphiques :
- Graphe à bulles
- Diagramme en barres
- Diagramme circulaire
- Diagramme radar
- Cartographie (si code ISO 3 ou code ISO 2 des pays)
Le flux JSON produit est identique à celui renvoyé par « distinct-by ».
distribute-by-date
Sert à créer des chronologies qui conservent les années sans document/de valeur nulle.
Cette routine est utilisée de manière optimale avec le format graphique « Diagramme à barres ».
Le flux JSON renvoyé se présente selon la structure {« _id », « value »}.
distribute-by-decadal
Sert à créer des chronologies en regroupant les valeurs par décennie (utile pour des années dispersées sur plusieurs siècles).
Cette routine est utilisée de manière optimale avec le format graphique « Diagramme à barres ».
Le flux JSON renvoyé se présente selon la structure {« _id », « value »}.
distribute-by-interval
Routine destinée à des graphiques pour lesquels on souhaite regrouper des valeurs (nombres entiers ou décimaux) dans des intervalles unitaires de pas “1”. Cette opération ne correspond pas à un arrondissement mais permet de discrétiser des valeurs décimales dans des intervalles unitaires (par exemple 0.99 et 0.01 seront considérés comme « 1 » tout comme 1.01 et 1.99 seront considérés comme « 2 » (soit dans l’intervalle entre 1 et 2).
Cette routine peut être utilisée avec les formats graphiques :
- Diagramme en barres
- Diagramme circulaire
- Diagramme radar
Le flux JSON renvoyé se présente selon la structure {« _id », « value »}.
filter
Identifie pour une sous-ressource donnée, toutes les ressources dans lesquelles cette sous-ressource est présente.
Formats généralement associés pour l’affichage du champ généré : « RessourcesGrid », « PaginatedTable », « PaginatedTable ».
get-fields
Pour utiliser des nombres affectés à des champs des ressources (pas de comptage, utilise la valeur numérique du champ), il faut pouvoir générer des paires _id /valeur contenant les valeurs de deux champs (en général, un libellé et un nombre, par exemple pour un graphique de type « camembert »).
Pour sélectionner le libellé, on donne l’identifiant du champ contenant le libellé comme identifiant1 puis on ajoute l’identifiant du champ contenant la valeur numérique comme identifiant2.
/api/run/get-fields/identifiant1/identifiant2/
Exemples de ressources:
| nom de fichier | Unitex-anglais | Unitex-français |
|---|---|---|
| wiley | 4460007 | 12832 |
| elsevier | 5879095 | 82652 |
| springer-journals | 1424762 | 20131 |
résultat de la routine:
{
"data": [
{
"_id": "wiley",
"value": 4460007
},
{
"_id": "elsevier",
"value": 5879095
},
{
"_id": "springer-journals",
"value": 1424762
}
]
}
graph-by
Croise les éléments pour un champ ou plusieurs champs et compte le nombre d’occurrences de chaque croisement.
Crée les paires (source et cible) entre les valeurs de 1 champ ou plusieurs champs (champs identiques ou différents) selon :
/api/run/graph-by/identifiant1/
/api/run/graph-by/identifiant1/identifiant2/
et compte, pour chaque paire, le nombre de co-occurrences.
Cette routine se comporte comme la routine decompose-by. Mais contrairement à celle-ci, elle n’interprète pas les paramètres associés aux graphiques.
Elle peut, en particulier, être utilisée avec les formats Réseau et Carte de chaleur
Attention : dans le cas où cette routine s’applique à plusieurs champs (/api/run/graph-by/identifiant1/identifiant2/), elle crée les paires identifiant1/identifiant2 mais aussi identifiant1/identifiant1 et identifiant2/identifiant2, ce qui peut ne pas être adapté pour un graphique réseau.
À la manière de « decompose-by », le format JSON renvoyé est sous la forme {« source », « target », « weight »).
group-and-sum-with
Ajoute, pour chaque élément d champ représenté (identifiant), toutes les valeurs du deuxième champ (valeur) correspondant
Crée les paires (source et cible) entre les valeurs de 1 champ ou plusieurs champs (champs identiques ou différents) selon :
Elle peut, en particulier, être utilisée avec les diagrammes à barre ou les graphiques sectoriels pour visualiser le montant total des APCs « Article processing charges » pour un critère donné (Année, Éditeur, Revue…)
Le flux JSON renvoyé se présente selon la structure {« _id », « value »}.
pairing-with
Croise les éléments pour un champ ou plusieurs champs et compte le nombre d’occurrences de chaque croisement.
Crée les paires (source et cible) entre les éléments de 2 champs (champs identiques ou différents) déclarés selon :
-
/api/run/pairing-with/identifiant1/identifiant1/
-
/api/run/pairing-with/identifiant1/identifiant2/
et compte, pour chaque paire, le nombre de co-occurrences.
Cette routine se comporte comme la routine cross-by. Contrairement à celle-ci elle n’interprète pas les paramètres associés aux graphiques.
Elle peut, en particulier, être utilisée avec les formats graphiques Réseau et Carte de chaleur.
Attention : dans le cas où cette routine s’applique à un seul champ (/api/run/pairing-with/identifiant1/identifiant1/), elle conserve les auto-paires (source et cible identiques). Cela peut être intéressant avec le format Carte de chaleur pour visualiser la diagonale, mais peut être gênant avec d’autres formats.
À la manière de « cross-by », le format JSON renvoyé est sous la forme {« source », « target », « weight »).
labeled-resources
À la manière de « all-document » récupère les champs de toutes les ressources du corpus, mais en enlevant les champs _id, publicationDate, uri, et total. Tous les autres champs sont fournis.
De plus, les chaînes numériques (comme « 123 ») sont converties en nombres (comme 123).
Cette routine est particulièrement utile pour le format « Graphique – Syntaxe Vega-Lite ».
Comme elle retourne tous les champs, aucun champ n’est fourni en paramètre.
Attention: ce sont les identifiants des champs qui sont fournis, pas leurs libellés.
Exemple de résultat:
[ { « z5Yi »: « May 14, 2019« , « uNp0 »: « multicat« , « cniQ »: 11350203 }, { « z5Yi »: « May 14, 2019« , « uNp0 »: « unitex« , « cniQ »: 2743607 }, { « z5Yi »: « May 14, 2019« , « uNp0 »: « teeft« , « cniQ »: 2148348 }, { « z5Yi »: « May 14, 2019« , « uNp0 »: « nb« , « cniQ »: 3180498 }, { « z5Yi »: « May 14, 2019« , « uNp0 »: « refbibs« , « cniQ »: 5655020 } ]
Remarque : L’utilisation de cette routine n’est pas recommandée lors de travaux sur des « datasets » massifs, car cela équivaut à exporter l’ensemble de la base de données dans la mémoire du navigateur ce qui peut provoquer de gros ralentissements en fonction de la mémoire vive disponible, de la taille du corpus et du nombre de champs.
sparql-query
Elle sert à faire des graphiques de distribution en prenant ses données dans un tripleStore et non dans Lodex.
Elle est adaptée pour réaliser les graphiques pouvant également utiliser la routine « distinct-by » :
- Graphe à bulles
- Diagramme à barres
- Diagramme circulaire
- Diagramme radar
À la manière de « distinct-by », le format JSON renvoyé est sous la forme {« source », « target », « weight »).
Version minimale de lodex : 9.8.1
Ce type de graphique nécessite la structure suivante : un champ total correspondant au nombre d’éléments un champ data qui est la liste des éléments à afficher dans le graphique. Chaque élément possède 2 champs également. Un champ _id qui correspond au nom de l’élément et un champ value qui correspond à la valeur numérique qui lui est associée.
Attention : créer directement sa requête dans le tripleStore de data.istex.fr via YASGUI
Copier le lien de partage –> ce lien sera la valeur à reporter dans un champ LODEX préalablement configuré.
Insérer ce lien dans un nouveau champ DATASET lodex et récupérer son identifiant (ici Kl67 )
Créer un autre champ type graphique au niveau du DATASET pour récupérer les informations de ce champ.
Cette routine doit être déclarée dans Value (Valeur) selon : /api/run/sparql-query/identifiant où identifiant représente le champ contenant la requête copiée depuis le yasgui de data.istex.fr*
sub-resources-asterplot
Affiche dans graphique de type « Aster Plot » les sous-ressources les plus fréquemment co-occurrentes avec une sous-ressource donnée -adaptation de la routine sub-resources-co-occurences).
Format associé : « Graphique – Aster Plot ».
sub-resources-co-occurences
Identifie les sou-ressources co-occurrentes avec une sous-ressource donnée et calcule le nombre de ces co-occurences.
Formats associés : « Autre – Tableau non paginé » et « Autre – Tableau paginé ».
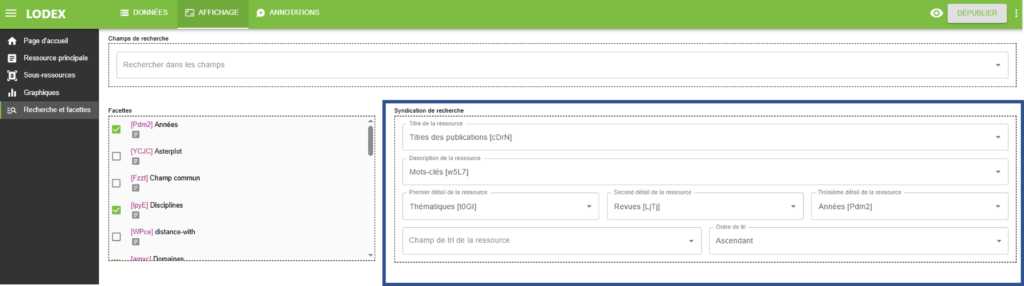
syndication
Récupère les champs paramétrés dans la zone Syndication dans l’onglet « Recherche et facettes » dans la partie « Affichage » et est en général utilisée avec le format Resources Grid pour représenter et fournir un accès direct à un certain nombre de ressources à partir de la page d’accueil.
syndication-from
Fait référence à une autre ressource du même jeu de données en liant les valeurs entre elles et non leurs arks. Il affiche ainsi les informations que l’on souhaite via les identifiants de la ressource.
Cette routine est, en particulier, utilisée avec le format Resources Grid pour représenter sur la page d’accueil les champs paramétrés dans syndication-from.
Exemple : l’instance revue de sommaire
Cette ressource récupère les informations d’une autre ressource via son identifiant ISSN déclaré dans une colonne bien spécifique portant l’identifiant nC6e. On reporte donc la valeur à la fin :
/api/run/syndication-from/**nC6e**/0300-4910
total-of
Ajoute toutes les valeurs numériques du champ sélectionné.
Format associé : « Texte – Chiffres en gras ».
tree-by
Permet de créer des graphiques en forme d’arbres représentant des données hiérarchisées (classification, taxonomies …) et d’afficher le nombre de documents concernés.
Format d’entrée obligatoire : JSON
Les valeurs du champ représenté sont listées dans un ordre précis : du plus générique au plus spécifique :
"categories": {
"wos": [
"1 - science",
"2 - marine & freshwater biology"
],
"scienceMetrix": [
"1 - natural sciences",
"2 - biology",
"3 - marine biology & hydrobiology"
],
"scopus": [
"1 - Life Sciences",
"2 - Agricultural and Biological Sciences",
"3 - Aquatic Science"
],
"inist": [
"1 - sciences appliquees, technologies et medecines",
"2 - sciences biologiques et medicales",
"3 - sciences biologiques fondamentales et appliquees. psychologie"
]
},
Crée des paires 2 à 2 entre les concepts spécifiques et plus génériques, et comptabilise le nombre de documents concernés par les concepts plus spécifiques de chaque segment.
Cette routine doit être appliquée à un champ représentant les noms des espèces ou les catégories scientifiques (termes les plus spécifiques d’une classification hiérarchique).
Un exemple est donné dans la galerie de modèles : Modèle « Animalia » : illustration de la construction d’un graphique hiérarchique.
Cette routine est destinée à être utilisée avec le format « Graphique -Graphique hiérarchique ».
ventilate-by
Compte, pour plusieurs éléments (source –> noms de colonnes) et pour plusieurs valeurs (target –> valeurs distinctes pour chaque colonne), le nombre de fois où chaque élément et même valeur apparait.
Formats associés : « Graphique – Réseaux » et « Graphique – Carte de chaleur ».
Cette routine peut aussi être utilisée pour produire des diagrammes à barres empilées ou groupées en utilisant une syntaxe Vega-Lite simplifiée.