Présentation
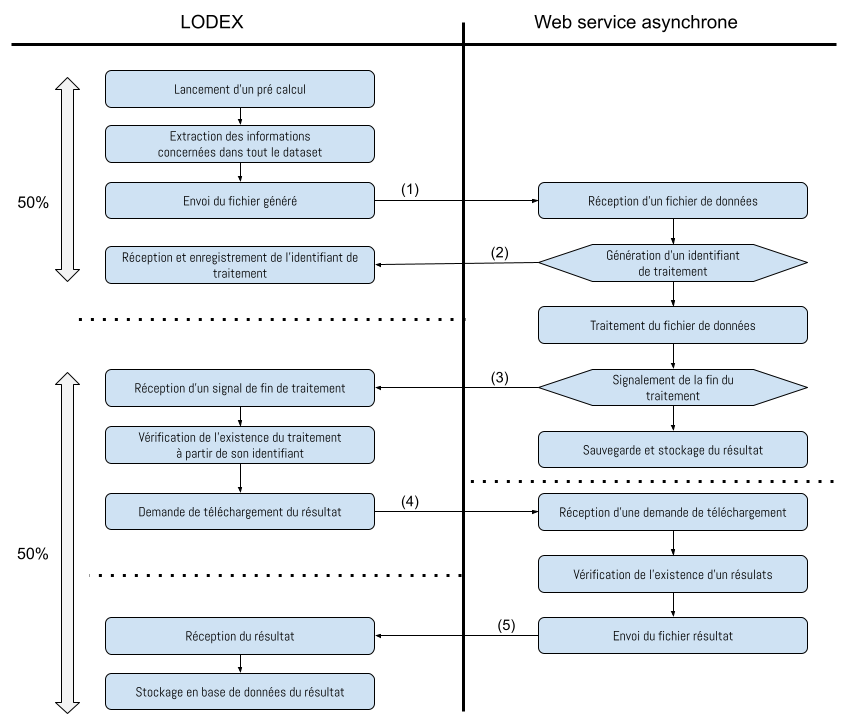
Les précalculs proposent de réaliser des calculs sur le jeu de données brut chargé dans Lodex (« dataset »). Les résultats de ces calculs sont stockés dans Lodex et peuvent être directement utilisés dans l’interface publique au travers de graphiques. Les calculs ne sont pas réalisés par Lodex mais sont externalisés dans un service web indépendant de Lodex.
Fonctionnement
Précalculs disponibles
- « dataHomogenise – Homogénéisation automatique de mots-clés » : homogénéise automatiquement un ensemble de mots-clés ou de listes de mots-clés issus d’un corpus en anglais.
- « Graph-segment » : crée des segments 2 à 2 avec tous les éléments d’un tableau et les agrège pour les compter. Les segments représentant toutes les associations possibles, ce traitement sert à créer des réseaux ou peut permettre de croiser des catégories.
- « ldaClass – Extraction de 6 thématiques d’un corpus » : extrait 15 thématiques (topics) d’un corpus. Ces dernières sont caractérisées par 10 mots puis chaque document s’en voit attribuer au moins une.
- « ldaClass – Extraction de 8 thématiques d’un corpus » : identique au précalcul précédent mais restreint à 8 thématiques par défaut au lieu de 6. Contrairement au précalcul précédent, celui-ci permet de paramétrer le nombre de topics à extraire via son url : « https://data-computer.services.istex.fr/v1/lda?nbTopic=8« .
- « ldaSegment – Extraction de 6 thématiques d’un corpus dans un format adapté à la création de graphiques » : crée 6 topics à partir de l’ensemble des documents d’un corpus. Chaque topic contient un champ « word » composé d’une liste de 10 mots les plus caractéristiques du topic, ainsi que d’un champ « weight » qui correspond au poids associé au sujet dans le document. Le texte doit être en anglais.
- « ldaSegment – Extraction de 8 thématiques d’un corpus dans un format adapté à la création de graphiques » : crée 8 topics à partir de l’ensemble des documents d’un corpus. Chaque topic contient un champ « word » composé d’une liste de 10 mots les plus caractéristiques du topic, ainsi que d’un champ « weight » qui correspond au poids associé au sujet dans le document. Le texte doit être en anglais. Contrairement au précalcul précédent, celui-ci permet de paramétrer le nombre de topics à extraire via son url : « https://data-computer.services.istex.fr/v1/lda-segment?nbTopic=8« .
- « noiseDetect – Détection de bruit d’un corpus » : repère la liste des identifiants des documents considérés comme du bruit dans un corpus. Il s’agit de documents considérés comme non pertinents.
- « Statistiques » : calcule une série de statistiques sur toutes les valeurs d’un champ (fréquence, moyenne, etc.)
- « Teeft eng – Extraction de termes anglais » : extrait les 10 termes anglais les plus spécifiques pour chaque document et additionne les fréquences des termes extraits.
- « Teeft fra – Extraction de termes français » : extrait les 10 termes français les plus spécifiques pour chaque document et additionne les fréquences des termes extraits.
- « TermSuite eng – Extraction de termes anglais » : extrait par défaut, les 500 termes anglais les plus spécifiques rencontrés à l’échelle d’un corpus de documents.
- « TermSuite fra – Extraction de termes français » : extrait par défaut, les 500 termes français les plus spécifiques rencontrés à l’échelle d’un corpus de documents.
- « textClustering – Extraction de clusters d’un corpus » : partitionne un corpus afin d’y classer les différents textes en fonction de leur similarité.
- « topRefExtract – Identifie les 10 publications les plus citées dans un corpus donné » : à partir des références citées de tout le corpus, il extrait les 10 plus citées.
- « topRefExtract – Identifie les N publications les plus citées dans un corpus donné, ici 4 » : à partir des références citées de tout le corpus, il extrait les 4 plus citées.
- « Tree-segment » :crée des segments glissants 2 à 2 de tous les éléments d’un tableau et les agrège pour les compter. Les segments étant glissants, ce traitement sert à créer un arbre hiérarchique.
Lien vers la liste des services web ISTEX TDM (précalculs et enrichissements) : https://services.istex.fr/category/services/.
Exemple : création d’une carte de chaleur (« Heatmap ») à l’aide du précalcul « graph-segment »
Les précalculs s’effectuent via des webservices exécutant un script utilisant directement des colonnes du jeu de données en tant qu’arguments entrants. Si l’on prend l’exemple d’un « dataset » comprenant deux colonnes « année de soutenance » et « discipline FR », en utilisant le webservice « graph-segment », il est possible d’obtenir un fichier JSON sous la forme « source, target, weight » contenant respectivement les années de soutenance, les disciplines ainsi que nombre d’occurrences correspondant à ce croisement.
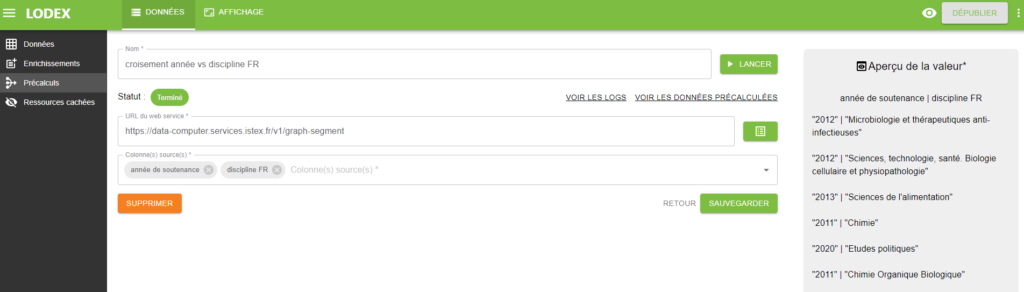
Les données produites peuvent ensuite être téléchargées en cliquant sur « VOIR LES DONNÉES PRÉCALCULÉES » : un aperçu de ces dernières est présenté avec un bouton permettant leur téléchargement.

Pour obtenir la carte de chaleur présentée ci-après à partir de ces données précalculées, il convient de créer un graphique en utilisant ces dernières comme données source (celles-ci ne sont pour le moment pas visibles dans Lodex mais peuvent tout de même être utilisées) et en leur appliquant la routine « segments-precomputed ». Ensuite, il suffit juste de formater l’affichage du résultat obtenu sous la forme « Graphique – Carte de chaleur ».
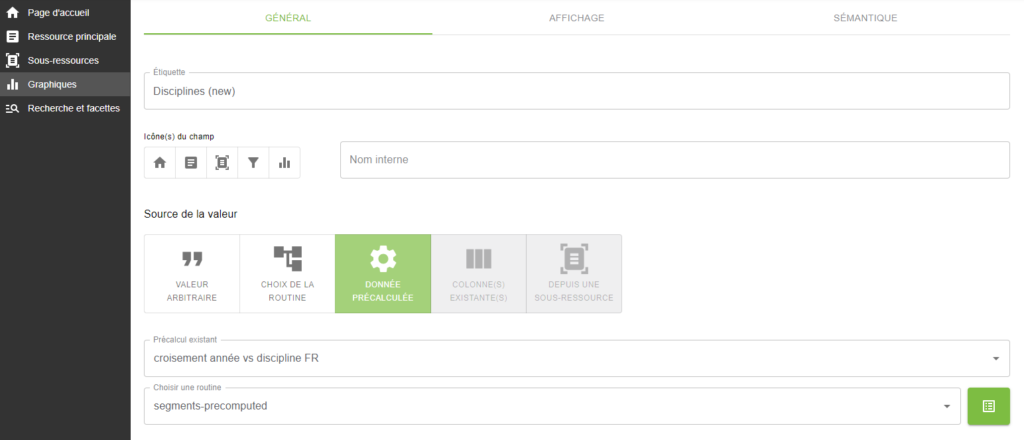
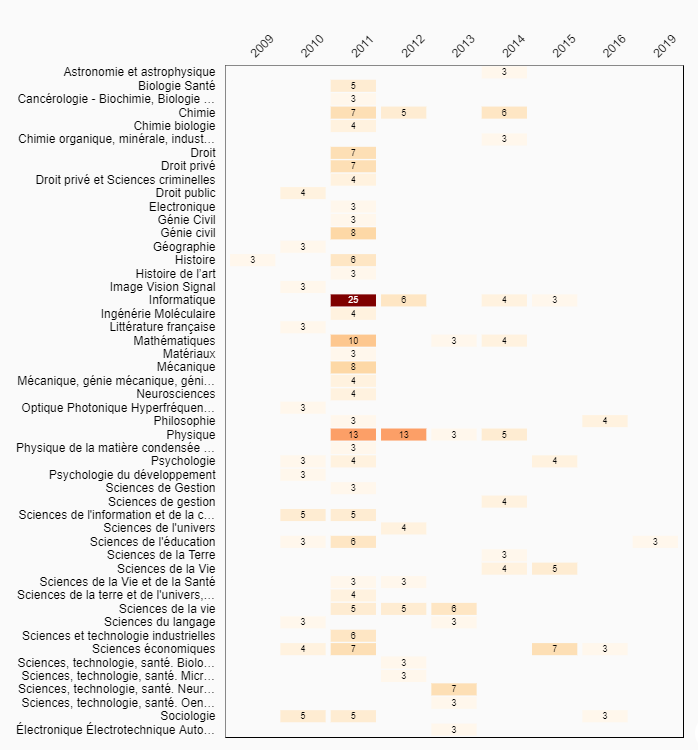
Cet exemple étant purement à usage démonstratif, il est tout de même intéressant de noter que le même résultat peut être obtenu en créant un graphique de type « Heatmap » à l’aide des routines « graph-by » ou « pairing-with » appliquées sur des ressources principales créées à partir des colonnes précédemment citées.