Cette section vise à illustrer 2 concepts : comment réceptionner des demandes de suppression de ressources d’un jeu de données et comment réaliser des suppressions de ressources en masse via l’import du fichier des annotations dans le jeu de données initial et l’utilisation d’un enrichissement permettant le repérage des documents à écarter d’un corpus massif dans le cas où ils seraient nombreux. La mise en œuvre conjointe de ces deux concepts pourrait être particulièrement utile dans le cadre de l’élimination de documents non pertinents vis-à-vis d’une thématique d’étude définie à partir d’un corpus très volumineux (50000 à 500000 documents par exemple).
Création d’un champ vide annotable via une liste contenant une valeur prédéfinie
Dans un premier temps, il convient pour l’administrateur de créer un champ vide dans la partie « Ressource principale » (invisible pour les utilisateurs mais visible par les contributeurs et administrateurs) que l’on peut intituler « Souhaitez-vous retirer cette ressource (Corriger du contenu) ? ». La configuration idoine pour utiliser par la suite l’enrichissement prévu pour le repérage des documents à supprimer en masse est présentée par les copies d’écran ci-dessous.
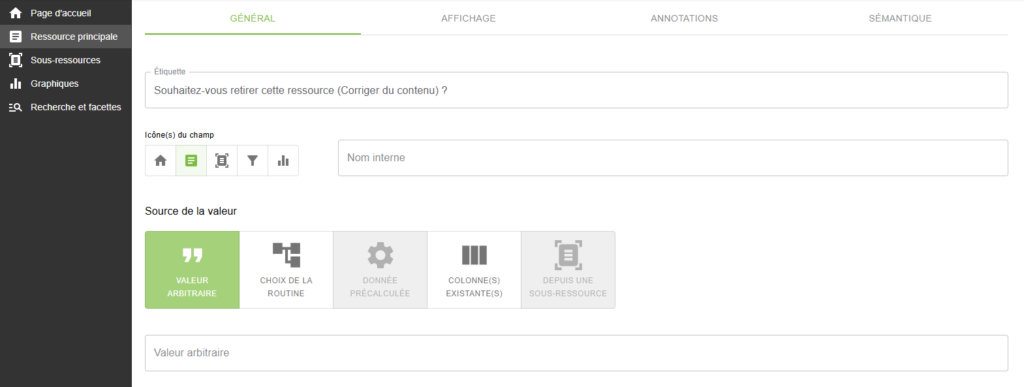
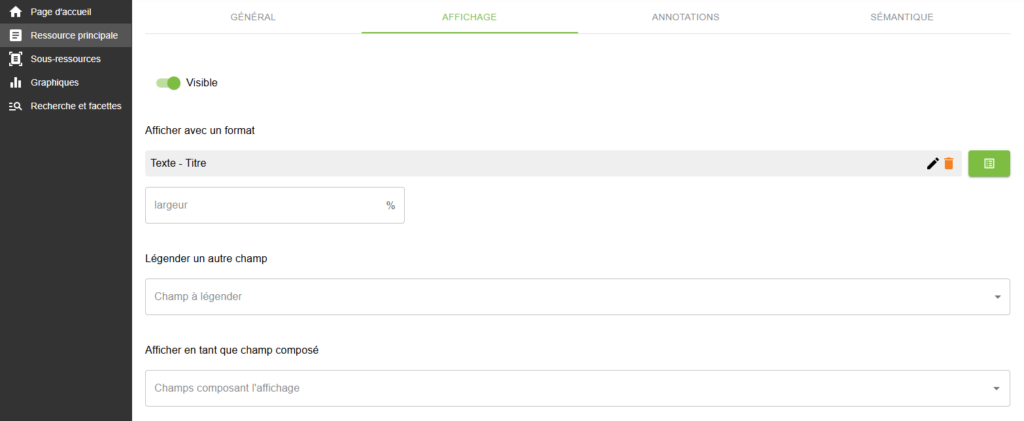
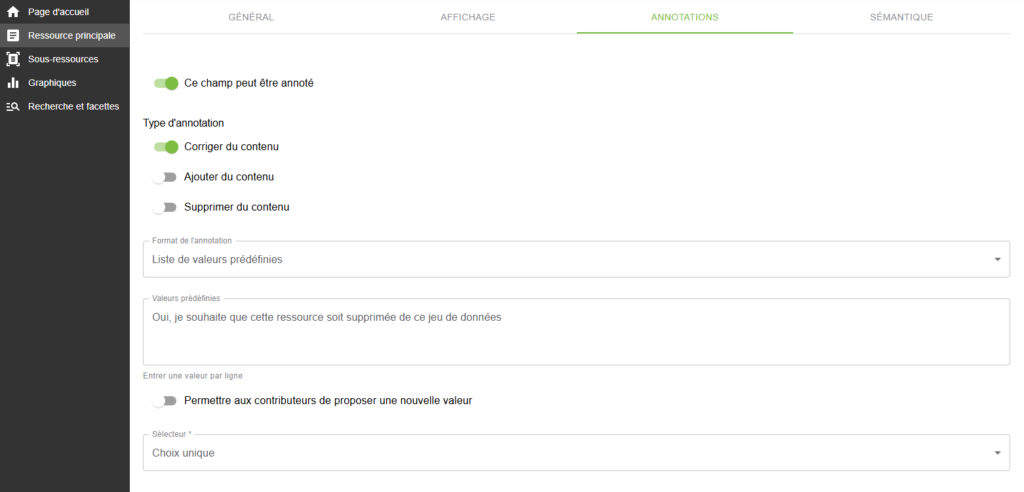
Le résultat pour le contributeur se présentera alors comme ci-dessous.
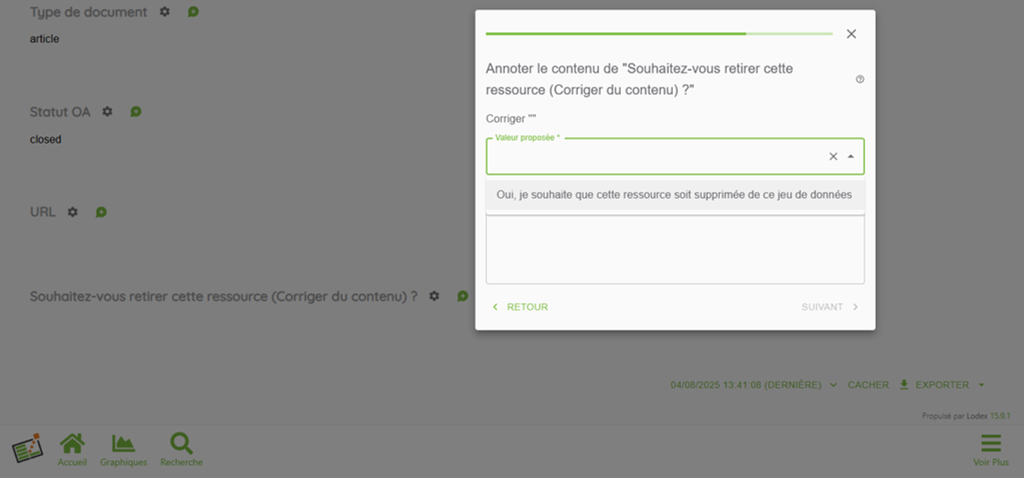
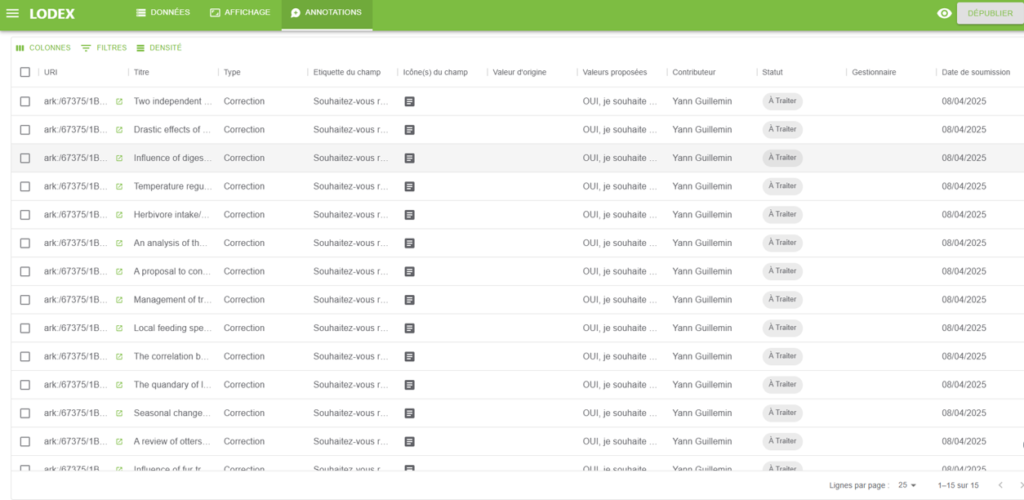
Et voici ce que pourrait voir un administrateur sur le tableau de bord de suivi des annotations. Il n’y a que 15 demandes de suppression dans cet exemple, mais si un corpus de plus de 100000 documents venait à être entièrement et méthodiquement « scanné » pour « coller » au plus proche d’une thématique très précise, le nombre de ressources à écarter pourrait avoisiner 1000 voire 5000 (soit entre 1% et 5%). La seconde partie de cette section montre comment s’y prendre dans ce genre de situation pour supprimer des ressources en masse.
Export des annotations puis importation dans le « dataset » initial et utilisation de 2 enrichissements pour trier les documents à supprimer du jeu de données
- Exporter les annotations au format JSON comme expliqué dans la section Export et import des annotations.
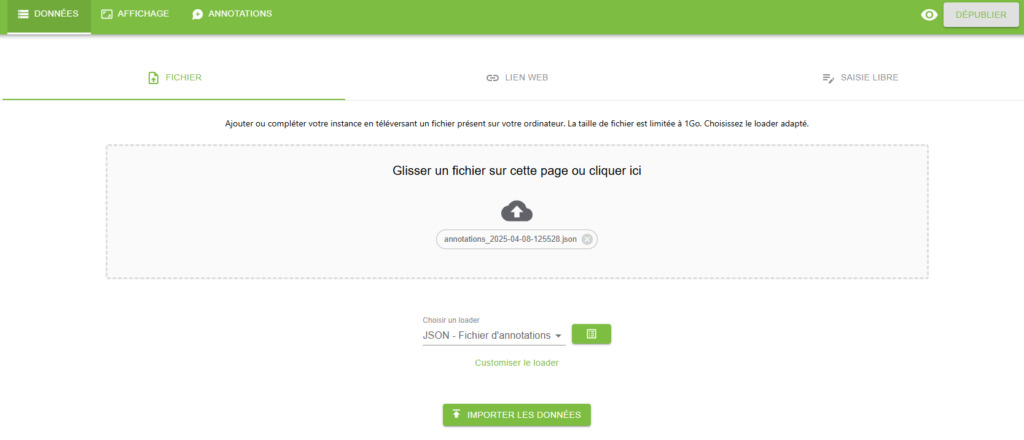
- Importer les annotations dans l’instance à corriger en tant que données (intégration dans le « dataset » initial) via le loader « JSON – Fichier d’annotations » (cf. copie d’écran ci-dessous).
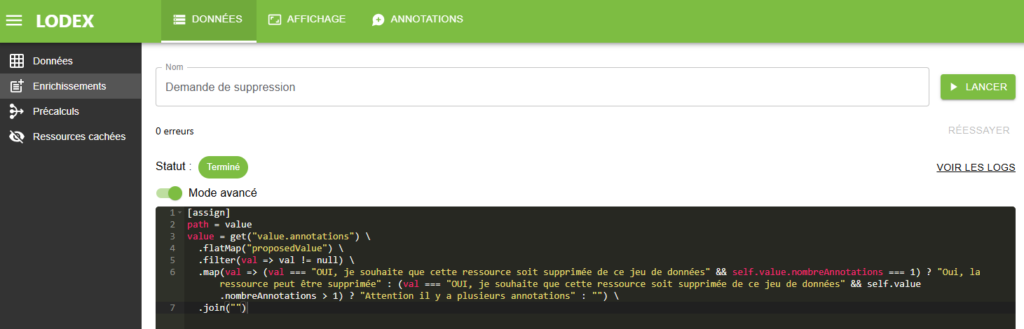
- Créer un enrichissement « nombre Annotations » comme expliqué dans la recette suivante : « Importer et traiter des annotations dans le dataset » et le lancer.
- Créer un deuxième enrichissement (que l’on peut nommer « Demande de suppression » par exemple) comme expliqué dans la recette citée ci-dessus et le lancer.
- Revenir dans l’onglet données et filtrer la colonne « Demande de suppression » avec l’opérateur « contient » la valeur « OUI »
- Cliquer sur le bouton « SUPPRIMER LE(S) LIGNES FILTRÉE(S) »

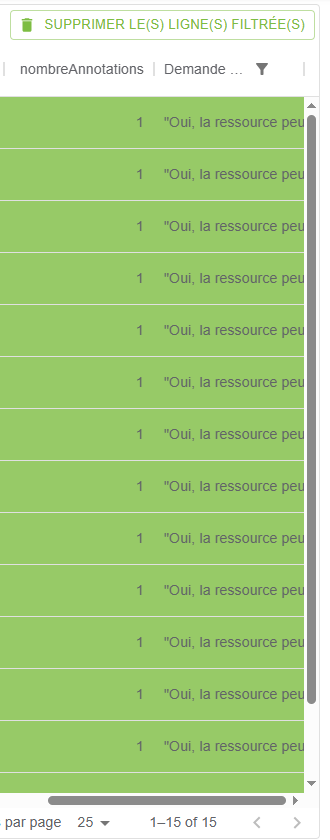
Le corpus en question comportait 4486 documents et n’en contient plus que 4471 après ces manipulations, les 15 documents indésirables ont été écartés en un clic. Il ne s’agit là que d’un exemple, mais cette procédure devrait permettre de gagner un temps précieux dans le cadre d’un « nettoyage » de grande ampleur.